Nov 27, JDN 2457690
(This topic was chosen by vote of my Patreons.)
In neoclassical theory, it is assumed (explicitly or implicitly) that human beings judge probability in something like the optimal Bayesian way: We assign prior probabilities to events, and then when confronted with evidence we infer using the observed data to update our prior probabilities to posterior probabilities. Then, when we have to make decisions, we maximize our expected utility subject to our posterior probabilities.
This, of course, is nothing like how human beings actually think. Even very intelligent, rational, numerate people only engage in a vague approximation of this behavior, and only when dealing with major decisions likely to affect the course of their lives. (Yes, I literally decide which universities to attend based upon formal expected utility models. Thus far, I’ve never been dissatisfied with a decision made that way.) No one decides what to eat for lunch or what to do this weekend based on formal expected utility models—or at least I hope they don’t, because that point the computational cost far exceeds the expected benefit.
So how do human beings actually think about probability? Well, a good place to start is to look at ways in which we systematically deviate from expected utility theory.
A classic example is the Allais paradox. See if it applies to you.
In game A, you get $1 million dollars, guaranteed.
In game B, you have a 10% chance of getting $5 million, an 89% chance of getting $1 million, but now you have a 1% chance of getting nothing.
Which do you prefer, game A or game B?
In game C, you have an 11% chance of getting $1 million, and an 89% chance of getting nothing.
In game D, you have a 10% chance of getting $5 million, and a 90% chance of getting nothing.
Which do you prefer, game C or game D?
I have to think about it for a little bit and do some calculations, and it’s still very hard because it depends crucially on my projected lifetime income (which could easily exceed $3 million with a PhD, especially in economics) and the precise form of my marginal utility (I think I have constant relative risk aversion, but I’m not sure what parameter to use precisely), but in general I think I want to choose game A and game C, but I actually feel really ambivalent, because it’s not hard to find plausible parameters for my utility where I should go for the gamble.
But if you’re like most people, you choose game A and game D.
There is no coherent expected utility by which you would do this.
Why? Either a 10% chance of $5 million instead of $1 million is worth risking a 1% chance of nothing, or it isn’t. If it is, you should play B and D. If it’s not, you should play A and C. I can’t tell you for sure whether it is worth it—I can’t even fully decide for myself—but it either is or it isn’t.
Yet most people have a strong intuition that they should take game A but game D. Why? What does this say about how we judge probability?
The leading theory in behavioral economics right now is cumulative prospect theory, developed by the great Kahneman and Tversky, who essentially founded the field of behavioral economics. It’s quite intimidating to try to go up against them—which is probably why we should force ourselves to do it. Fear of challenging the favorite theories of the great scientists before us is how science stagnates.
I wrote about it more in a previous post, but as a brief review, cumulative prospect theory says that instead of judging based on a well-defined utility function, we instead consider gains and losses as fundamentally different sorts of thing, and in three specific ways:
First, we are loss-averse; we feel a loss about twice as intensely as a gain of the same amount.
Second, we are risk-averse for gains, but risk-seeking for losses; we assume that gaining twice as much isn’t actually twice as good (which is almost certainly true), but we also assume that losing twice as much isn’t actually twice as bad (which is almost certainly false and indeed contradictory with the previous).
Third, we judge probabilities as more important when they are close to certainty. We make a large distinction between a 0% probability and a 0.0000001% probability, but almost no distinction at all between a 41% probability and a 43% probability.
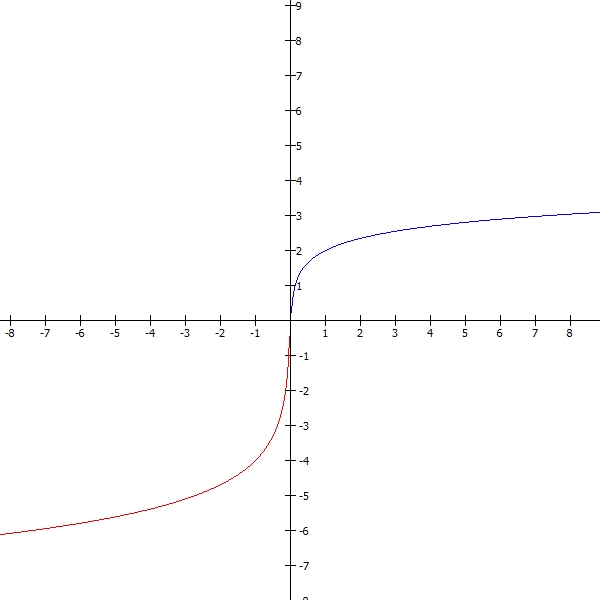
That last part is what I want to focus on for today. In Kahneman’s model, this is a continuous, monotonoic function that maps 0 to 0 and 1 to 1, but systematically overestimates probabilities below but near 1/2 and systematically underestimates probabilities above but near 1/2.
It looks something like this, where red is true probability and blue is subjective probability:

I don’t believe this is actually how humans think, for two reasons:
- It’s too hard. Humans are astonishingly innumerate creatures, given the enormous processing power of our brains. It’s true that we have some intuitive capacity for “solving” very complex equations, but that’s almost all within our motor system—we can “solve a differential equation” when we catch a ball, but we have no idea how we’re doing it. But probability judgments are often made consciously, especially in experiments like the Allais paradox; and the conscious brain is terrible at math. It’s actually really amazing how bad we are at math. Any model of normal human judgment should assume from the start that we will not do complicated math at any point in the process. Maybe you can hypothesize that we do so subconsciously, but you’d better have a good reason for assuming that.
- There is no reason to do this. Why in the world would any kind of optimization system function this way? You start with perfectly good probabilities, and then instead of using them, you subject them to some bizarre, unmotivated transformation that makes them less accurate and costs computing power? You may as well hit yourself in the head with a brick.
So, why might it look like we are doing this? Well, my proposal, admittedly still rather half-baked, is that human beings don’t assign probabilities numerically at all; we assign them categorically.
You may call this, for lack of a better term, categorical prospect theory.
My theory is that people don’t actually have in their head “there is an 11% chance of rain today” (unless they specifically heard that from a weather report this morning); they have in their head “it’s fairly unlikely that it will rain today”.
That is, we assign some small number of discrete categories of probability, and fit things into them. I’m not sure what exactly the categories are, and part of what makes my job difficult here is that they may be fuzzy-edged and vary from person to person, but roughly speaking, I think they correspond to the sort of things psychologists usually put on Likert scales in surveys: Impossible, almost impossible, very unlikely, unlikely, fairly unlikely, roughly even odds, fairly likely, likely, very likely, almost certain, certain. If I’m putting numbers on these probability categories, they go something like this: 0, 0.001, 0.01, 0.10, 0.20, 0.50, 0.8, 0.9, 0.99, 0.999, 1.
Notice that this would preserve the same basic effect as cumulative prospect theory: You care a lot more about differences in probability when they are near 0 or 1, because those are much more likely to actually shift your category. Indeed, as written, you wouldn’t care about a shift from 0.4 to 0.6 at all, despite caring a great deal about a shift from 0.001 to 0.01.
How does this solve the above problems?
- It’s easy. Not only don’t you compute a probability and then recompute it for no reason; you never even have to compute it precisely. Just get it within some vague error bounds and that will tell you what box it goes in. Instead of computing an approximation to a continuous function, you just slot things into a small number of discrete boxes, a dozen at the most.
- That explains why we would do it: It’s easy. Our brains need to conserve their capacity, and they did especially in our ancestral environment when we struggled to survive. Rather than having to iterate your approximation to arbitrary precision, you just get within 0.1 or so and call it a day. That saves time and computing power, which saves energy, which could save your life.
What new problems have I introduced?
- It’s very hard to know exactly where people’s categories are, if they vary between individuals or even between situations, and whether they are fuzzy-edged.
- If you take the model I just gave literally, even quite large probability changes will have absolutely no effect as long as they remain within a category such as “roughly even odds”.
With regard to 2, I think Kahneman may himself be able to save me, with his dual process theory concept of System 1 and System 2. What I’m really asserting is that System 1, the fast, intuitive judgment system, operates on these categories. System 2, on the other hand, the careful, rational thought system, can actually make use of proper numerical probabilities; it’s just very costly to boot up System 2 in the first place, much less ensure that it actually gets the right answer.
How might we test this? Well, I think that people are more likely to use System 1 when any of the following are true:
- They are under harsh time-pressure
- The decision isn’t very important
- The intuitive judgment is fast and obvious
And conversely they are likely to use System 2 when the following are true:
- They have plenty of time to think
- The decision is very important
- The intuitive judgment is difficult or unclear
So, it should be possible to arrange an experiment varying these parameters, such that in one treatment people almost always use System 1, and in another they almost always use System 2. And then, my prediction is that in the System 1 treatment, people will in fact not change their behavior at all when you change the probability from 15% to 25% (fairly unlikely) or 40% to 60% (roughly even odds).
To be clear, you can’t just present people with this choice between game E and game F:
Game E: You get a 60% chance of $50, and a 40% chance of nothing.
Game F: You get a 40% chance of $50, and a 60% chance of nothing.
People will obviously choose game E. If you can directly compare the numbers and one game is strictly better in every way, I think even without much effort people will be able to choose correctly.
Instead, what I’m saying is that if you make the following offers to two completely different sets of people, you will observe little difference in their choices, even though under expected utility theory you should.
Group I receives a choice between game E and game G:
Game E: You get a 60% chance of $50, and a 40% chance of nothing.
Game G: You get a 100% chance of $20.
Group II receives a choice between game F and game G:
Game F: You get a 40% chance of $50, and a 60% chance of nothing.
Game G: You get a 100% chance of $20.
Under two very plausible assumptions about marginal utility of wealth, I can fix what the rational judgment should be in each game.
The first assumption is that marginal utility of wealth is decreasing, so people are risk-averse (at least for gains, which these are). The second assumption is that most people’s lifetime income is at least two orders of magnitude higher than $50.
By the first assumption, group II should choose game G. The expected income is precisely the same, and being even ever so slightly risk-averse should make you go for the guaranteed $20.
By the second assumption, group I should choose game E. Yes, there is some risk, but because $50 should not be a huge sum to you, your risk aversion should be small and the higher expected income of $30 should sway you.
But I predict that most people will choose game G in both cases, and (within statistical error) the same proportion will choose F as chose E—thus showing that the difference between a 40% chance and a 60% chance was in fact negligible to their intuitive judgments.
However, this doesn’t actually disprove Kahneman’s theory; perhaps that part of the subjective probability function is just that flat. For that, I need to set up an experiment where I show discontinuity. I need to find the edge of a category and get people to switch categories sharply. Next week I’ll talk about how we might pull that off.