JDN 2456173 EDT 17:32.
Since I’ve been emphasizing the “economics” side of things a lot lately, I decided this week to focus more on the “cognitive” side. Today’s topic comes from cutting-edge research in cognitive science and neuroeconomics, so we still haven’t ironed out all the details.
The question we are trying to answer is an incredibly basic one: How do we make decisions? Given the vast space of possible behaviors human beings can engage in, how do we determine which ones we actually do?
There are actually two phases of decision-making.
The first phase is alternative generation, in which we come up with a set of choices. Some ideas occur to us, others do not; some are familiar and come to mind easily, others only appear after careful consideration. Techniques like brainstorming exist to help us with this task, but none of them are really very good; one of the most important bottlenecks in human cognition is the individual capacity to generate creative alternatives. The task is mind-bogglingly complex; the number of possible choices you could make at any given moment is already vast, and with each passing moment the number of possible behavioral sequences grows exponentially. Just think about all the possible sentences I could type write now, and then think about how incredibly narrow a space of possible behavioral options it is to assume that I’m typing sentences.
Most of the world’s innovation can ultimately be attributed to better alternative generation; particular with regard to social systems, but in many cases even with regard to technologies, the capability existed for decades or even centuries but the idea simply never occurred to anyone. (You can see this by looking at the work of Heron of Alexandria and Leonardo da Vinci; the capacity to build these machines existed, and a handful of individuals were creative enough to actually try it, but it never occurred to anyone that there could be enormous, world-changing benefits to expanding these technologies for mass production.)
Unfortunately, we basically don’t understand alternative generation at all. It’s an almost complete gap in our understanding of human cognition. It actually has a lot to do with some of the central unsolved problems of cognitive science and artificial intelligence; if we could create a computer that is capable of creative thought, we would basically make human beings obsolete once and for all. (Oddly enough, physical labor is probably where human beings would still be necessary the longest; robots aren’t yet very good at climbing stairs or lifting irregularly-shaped objects, much less giving haircuts or painting on canvas.)
The second part is what most “decision-making” research is actually about, and I’ll call it alternative selection. Once you have a list of two, three or four viable options—rarely more than this, as I’ll talk about more in a moment—how do you go about choosing the one you’ll actually do?
This is a topic that has undergone considerable research, and we’re beginning to make progress. The leading models right now are variants of drift-diffusion (hence the title of the post), and these models have the very appealing property that they are neurologically plausible, predictively accurate, and yet close to rationally optimal.
Drift-diffusion models basically are, as I said in the subtitle, a stock market in your brain. Picture the stereotype of the trading floor of the New York Stock Exchange, with hundreds of people bustling about, shouting “Buy!” “Sell!” “Buy!” with the price going up with every “Buy!” and down with every “Sell!”; in reality the NYSE isn’t much like that, and hasn’t been for decades, because everyone is staring at a screen and most of the trading is automated and occurs in microseconds. (It’s kind of like how if you draw a cartoon of a doctor, they will invariably be wearing a head mirror, but if you’ve actually been to a doctor lately, they don’t actually wear those anymore.)
Drift-diffusion, however, is like that. Let’s say we have a decision to make, “Yes” or “No”. Thousands of neurons devoted to that decision start firing, some saying “Yes”, exciting other “Yes” neurons and inhibiting “No” neurons, while others say “No”, exciting other “No” neurons and inhibiting other “Yes” neurons. New information feeds in, triggering some to “Yes” and others to “No”. The resulting process behaves like a random walk, specifically a trend random walk, where the intensity of the trend is determined by whatever criteria you are feeding into the decision. The decision will be made when a certain threshold is reached, say, 95% agreement among all neurons.
I wrote a little R program to demonstrate drift-diffusion models; the images I’ll be showing are R plots from that program. The graphs represent the aggregated “opinion” of all the deciding neurons; as you go from left to right, time passes, and the opinions “drift” toward one side or the other. For these graphs, the top of the graph represents the better choice.
It may actually be easiest to understand if you imagine that we are choosing a belief; new evidence accumulates that pushes us toward the correct answer (top) or the incorrect answer (bottom), because even a true belief will have some evidence that seems to be against it. You encounter this evidence more or less randomly (or do you?), and which belief you ultimately form will depend upon both how strong the evidence is and how thoughtful you are in forming your beliefs.
If the evidence is very strong (or in general, the two choices are very different), the trend will be very strong, and you’ll almost certainly come to a decision very quickly:
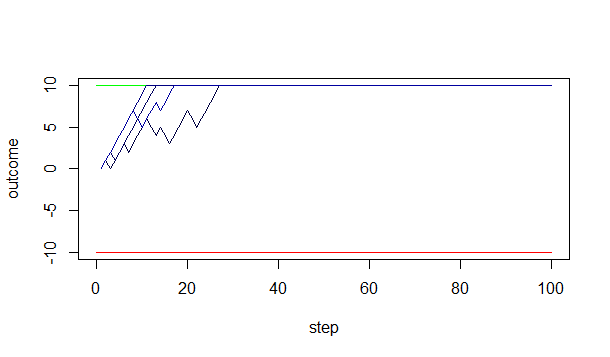
If the evidence is weaker (the two choices are very similar), the trend will be much weaker, and it will take much longer to make a decision:
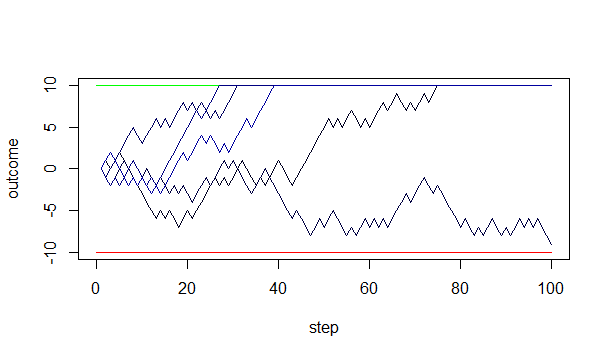
One way to make a decision faster would be to have a weaker threshold, like 75% agreement instead of 95%; but this has the downside that it can result in making the wrong choice. Notice how some of the paths go down to the bottom, which in this case is the worse choice:

But if there is actually no difference between the two options, a low threshold is good, because you don’t spend time waffling over a pointless decision. (I know that I’ve had a problem with that in real life, spending too long making a decision that ultimately is of minor importance; my drift thresholds are too high!) With a low threshold, you get it over with:

With a high threshold, you can go on for ages:

This is the difference between indifferent about a decision and being ambivalent. If you are indifferent, you are dealing with two small amounts of utility and it doesn’t really matter which one you choose. If you are ambivalent, you are dealing with two large amounts of utility and it’s very important to get it right—but you aren’t sure which one to choose. If you are indifferent, you should use a low threshold and get it over with; but if you are ambivalent, it actually makes sense to keep your threshold high and spend a lot of time thinking about the problem in order to be sure you get it right.
It’s also possible to set a higher threshold for one option than the other; I think this is actually what we’re doing when we exhibit many cognitive biases like confirmation bias. If the decision you’re making is between keeping your current beliefs and changing them to something else, your diffusion space actually looks more like this:
You’ll only make the correct choice (top) if you set equal thresholds (meaning you reason fairly instead of exhibiting cognitive biases) and high thresholds (meaning you spend sufficient time thinking about the question). If I may change to a sports metaphor, people tend to move the goalposts—the team “change your mind” has to kick a lot further than the team “keep your current belief”.
We can also extend drift-diffusion models to changing your mind (or experiencing regret such as “buyer’s remorse“) if we assume that the system doesn’t actually cut off once it reaches a threshold; the threshold makes us take the action, but then our neurons keep on arguing it out in the background. We may hover near the threshold or soar off into absolute certainty—but on the other hand we may waffle all the way back to the other decision:

There are all sorts of generalizations and extensions of drift-diffusion models, but these basic ones should give you a sense of how useful they are. More importantly, they are accurate; drift-diffusion models produce very sharp mathematical predictions about human behavior, and in general these predictions are verified in experiments.
The main reason we started using drift-diffusion models is that they account very well for the fact that decisions become more accurate when we spend more time on them. The way they do that is quite elegant: Under harsher time pressure, we use lower thresholds, which speeds up the process but also introduces more errors. When we don’t have time pressure, we use high thresholds and take a long time, but almost always make the right decision.
Under certain (rather narrow) circumstances, drift-diffusion models can actually be equivalent to the optimal Bayesian model. These models can also be extended for use in purchasing choices, and one day we will hopefully have a stock-market-in-the-brain model of actual stock market decisions!
Drift-diffusion models are based on decisions between two alternatives with only one relevant attribute under consideration, but they are being expanded to decisions with multiple attributes and decisions with multiple alternatives; the fact that this is difficult is in my opinion not a bug but a feature—decisions with multiple alternatives and attributes are actually difficult for human beings to make. The fact that drift-diffusion models have difficulty with the very situations that human beings have difficulty with provides powerful evidence that drift-diffusion models are accurately representing the processes that go on inside a human brain. I’d be worried if it were too easy to extend the models to complex decisions—it would suggest that our model is describing a more flexible decision process than the one human beings actually use. Human decisions really do seem to be attempts to shoehorn two-choice single-attribute decision methods onto more complex problems, and a lot of mistakes we make are attributable to that.
In particular, the phenomena of analysis paralysis and the paradox of choice are easily explained this way. Why is it that when people are given more alternatives, they often spend far more time trying to decide and often end up less satisfied than they were before? This makes sense if, when faced with a large number of alternatives, we spend time trying to compare them pairwise on every attribute, and then get stuck with a whole bunch of incomparable pairwise comparisons that we then have to aggregate somehow. If we could simply assign a simple utility value to each attribute and sum them up, adding new alternatives should only increase the time required by a small amount and should never result in a reduction in final utility.
When I have an important decision to make, I actually assemble a formal utility model, as I did recently when deciding on a new computer to buy (it should be in the mail any day now!). The hardest part, however, is assigning values to the coefficients in the model; just how much am I willing to spend for an extra gigabyte of RAM, anyway? How exactly do those CPU benchmarks translate into dollar value for me? I can clearly tell that this is not the native process of my mental architecture.
No, alas, we seem to be stuck with drift-diffusion, which is nearly optimal for choices with two alternatives on a single attribute, but actually pretty awful for multiple-alternative multiple-attribute decisions. But perhaps by better understanding our suboptimal processes, we can rearrange our environment to bring us closer to optimal conditions—or perhaps, one day, change the processes themselves!