JDN 2457061 PST 14:18.
Today’s topic is called prospect theory. Prospect theory is basically what put cognitive economics on the map; it was the knock-down argument that Kahneman used to show that human beings are not completely rational in their economic decisions. It all goes back to a 1979 paper by Kahneman and Tversky that now has 34000 citations (yes, we’ve been having this argument for a rather long time now). In the 1990s it was refined into cumulative prospect theory, which is more mathematically precise but basically the same idea.
What was that argument? People buy both insurance and lottery tickets.
The “both” is very important. Buying insurance can definitely be rational—indeed, typically is. Buying lottery tickets could theoretically be rational, under very particular circumstances. But they cannot both be rational at the same time.
To see why, let’s talk some more about marginal utility of wealth. Recall that a dollar is not worth the same to everyone; to a billionaire a dollar is a rounding error, to most of us it is a bottle of Coke, but to a starving child in Ghana it could be life itself. We typically observe diminishing marginal utility of wealth—the more money you have, the less another dollar is worth to you.
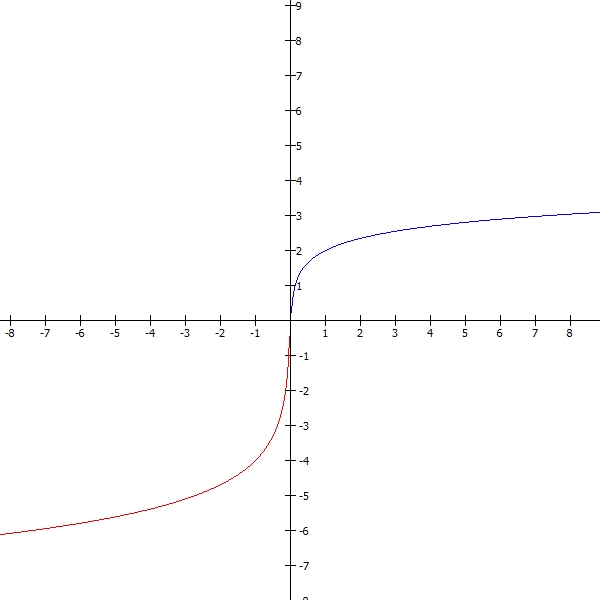
If we sketch a graph of your utility versus wealth it would look something like this:
Notice how it increases as your wealth increases, but at a rapidly diminishing rate.
If you have diminishing marginal utility of wealth, you are what we call risk-averse. If you are risk-averse, you’ll (sometimes) want to buy insurance. Let’s suppose the units on that graph are tens of thousands of dollars. Suppose you currently have an income of $50,000. You are offered the chance to pay $10,000 a year to buy unemployment insurance, so that if you lose your job, instead of making $10,000 on welfare you’ll make $30,000 on unemployment. You think you have about a 20% chance of losing your job.
If you had constant marginal utility of wealth, this would not be a good deal for you. Your expected value of money would be reduced if you buy the insurance: Before you had an 80% chance of $50,000 and a 20% chance of $10,000 so your expected amount of money is $42,000. With the insurance you have an 80% chance of $40,000 and a 20% chance of $30,000 so your expected amount of money is $38,000. Why would you take such a deal? That’s like giving up $4,000 isn’t it?
Well, let’s look back at that utility graph. At $50,000 your utility is 1.80, uh… units, er… let’s say QALY. 1.80 QALY per year, meaning you live 80% better than the average human. Maybe, I guess? Doesn’t seem too far off. In any case, the units of measurement aren’t that important.

By buying insurance your effective income goes down to $40,000 per year, which lowers your utility to 1.70 QALY. That’s a fairly significant hit, but it’s not unbearable. If you lose your job (20% chance), you’ll fall down to $30,000 and have a utility of 1.55 QALY. Again, noticeable, but bearable. Your overall expected utility with insurance is therefore 1.67 QALY.
But what if you don’t buy insurance? Well then you have a 20% chance of taking a big hit and falling all the way down to $10,000 where your utility is only 1.00 QALY. Your expected utility is therefore only 1.64 QALY. You’re better off going with the insurance.
And this is how insurance companies make a profit (well; the legitimate way anyway; they also like to gouge people and deny cancer patients of course); on average, they make more from each customer than they pay out, but customers are still better off because they are protected against big losses. In this case, the insurance company profits $4,000 per customer per year, customers each get 30 milliQALY per year (about the same utility as an extra $2,000 more or less), everyone is happy.
But if this is your marginal utility of wealth—and it most likely is, approximately—then you would never want to buy a lottery ticket. Let’s suppose you actually have pretty good odds; it’s a 1 in 1 million chance of $1 million for a ticket that costs $2. This means that the state is going to take in about $2 million for every $1 million they pay out to a winner.
That’s about as good as your odds for a lottery are ever going to get; usually it’s more like a 1 in 400 million chance of $150 million for $1, which is an even bigger difference than it sounds, because $150 million is nowhere near 150 times as good as $1 million. It’s a bit better from the state’s perspective though, because they get to receive $400 million for every $150 million they pay out.
For your convenience I have zoomed out the graph so that you can see 100, which is an income of $1 million (which you’ll have this year if you win; to get it next year, you’ll have to play again). You’ll notice I did not have to zoom out the vertical axis, because 20 times as much money only ends up being about 2 times as much utility. I’ve marked with lines the utility of $50,000 (1.80, as we said before) versus $1 million (3.30).

What about the utility of $49,998 which is what you’ll have if you buy the ticket and lose? At this number of decimal places you can’t see the difference, so I’ll need to go out a few more. At $50,000 you have 1.80472 QALY. At $49,998 you have 1.80470 QALY. That $2 only costs you 0.00002 QALY, 20 microQALY. Not much, really; but of course not, it’s only $2.
How much does the 1 in 1 million chance of $1 million give you? Even less than that. Remember, the utility gain for going from $50,000 to $1 million is only 1.50 QALY. So you’re adding one one-millionth of that in expected utility, which is of course 1.5 microQALY, or 0.0000015 QALY.
That $2 may not seem like it’s worth much, but that 1 in 1 million chance of $1 million is worth less than one tenth as much. Again, I’ve tried to make these figures fairly realistic; they are by no means exact (I don’t actually think $49,998 corresponds to exactly 1.804699 QALY), but the order of magnitude difference is right. You gain about ten times as much utility from spending that $2 on something you want than you do on taking the chance at $1 million.
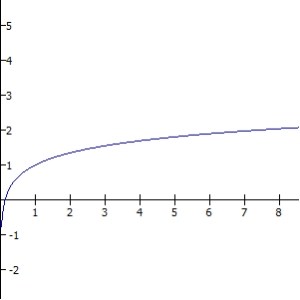
I said before that it is theoretically possible for you to have a utility function for which the lottery would be rational. For that you’d need to have increasing marginal utility of wealth, so that you could be what we call risk-seeking. Your utility function would have to look like this:

There’s no way marginal utility of wealth looks like that. This would be saying that it would hurt Bill Gates more to lose $1 than it would hurt a starving child in Ghana, which makes no sense at all. (It certainly would makes you wonder why he’s so willing to give it to them.) So frankly even if we didn’t buy insurance the fact that we buy lottery tickets would already look pretty irrational.
But in order for it to be rational to buy both lottery tickets and insurance, our utility function would have to be totally nonsensical. Maybe it could look like this or something; marginal utility decreases normally for awhile, and then suddenly starts going upward again for no apparent reason:
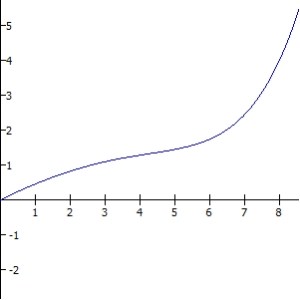
Clearly it does not actually look like that. Not only would this mean that Bill Gates is hurt more by losing $1 than the child in Ghana, we have this bizarre situation where the middle class are the people who have the lowest marginal utility of wealth in the world. Both the rich and the poor would need to have higher marginal utility of wealth than we do. This would mean that apparently yachts are just amazing and we have no idea. Riding a yacht is the pinnacle of human experience, a transcendence beyond our wildest imaginings; and riding a slightly bigger yacht is even more amazing and transcendent. Love and the joy of a life well-lived pale in comparison to the ecstasy of adding just one more layer of gold plate to your Ferrari collection.
Where increasing marginal utility is ridiculous, this is outright special pleading. You’re just making up bizarre utility functions that perfectly line up with whatever behavior people happen to have so that you can still call it rational. It’s like saying, “It could be perfectly rational! Maybe he enjoys banging his head against the wall!”
Kahneman and Tversky had a better idea. They realized that human beings aren’t so great at assessing probability, and furthermore tend not to think in terms of total amounts of wealth or annual income at all, but in terms of losses and gains. Through a series of clever experiments they showed that we are not so much risk-averse as we are loss-averse; we are actually willing to take more risk if it means that we will be able to avoid a loss.
In effect, we seem to be acting as if our utility function looks like this, where the zero no longer means “zero income”, it means “whatever we have right now“:

We tend to weight losses about twice as much as gains, and we tend to assume that losses also diminish in their marginal effect the same way that gains do. That is, we would only take a 50% chance to lose $1000 if it meant a 50% chance to gain $2000; but we’d take a 10% chance at losing $10,000 to save ourselves from a guaranteed loss of $1000.
This can explain why we buy insurance, provided that you frame it correctly. One of the things about prospect theory—and about human behavior in general—is that it exhibits framing effects: The answer we give depends upon the way you ask the question. That’s so totally obviously irrational it’s honestly hard to believe that we do it; but we do, and sometimes in really important situations. Doctors—doctors—will decide a moral dilemma differently based on whether you describe it as “saving 400 out of 600 patients” or “letting 200 out of 600 patients die”.
In this case, you need to frame insurance as the default option, and not buying insurance as an extra risk you are taking. Then saving money by not buying insurance is a gain, and therefore less important, while a higher risk of a bad outcome is a loss, and therefore important.
If you frame it the other way, with not buying insurance as the default option, then buying insurance is taking a loss by making insurance payments, only to get a gain if the insurance pays out. Suddenly the exact same insurance policy looks less attractive. This is a big part of why Obamacare has been effective but unpopular. It was set up as a fine—a loss—if you don’t buy insurance, rather than as a bonus—a gain—if you do buy insurance. The latter would be more expensive, but we could just make it up by taxing something else; and it might have made Obamacare more popular, because people would see the government as giving them something instead of taking something away. But the fine does a better job of framing insurance as the default option, so it motivates more people to actually buy insurance.
But even that would still not be enough to explain how it is rational to buy lottery tickets (Have I mentioned how it’s really not a good idea to buy lottery tickets?), because buying a ticket is a loss and winning the lottery is a gain. You actually have to get people to somehow frame not winning the lottery as a loss, making winning the default option despite the fact that it is absurdly unlikely. But I have definitely heard people say things like this: “Well if my numbers come up and I didn’t play that week, how would I feel then?” Pretty bad, I’ll grant you. But how much you wanna bet that never happens? (They’ll bet… the price of the ticket, apparently.)
In order for that to work, people either need to dramatically overestimate the probability of winning, or else ignore it entirely. Both of those things totally happen.
First, we overestimate the probability of rare events and underestimate the probability of common events—this is actually the part that makes it cumulative prospect theory instead of just regular prospect theory. If you make a graph of perceived probability versus actual probability, it looks like this:

We don’t make much distinction between 40% and 60%, even though that’s actually pretty big; but we make a huge distinction between 0% and 0.00001% even though that’s actually really tiny. I think we basically have categories in our heads: “Never, almost never, rarely, sometimes, often, usually, almost always, always.” Moving from 0% to 0.00001% is going from “never” to “almost never”, but going from 40% to 60% is still in “often”. (And that for some reason reminded me of “Well, hardly ever!”)
But that’s not even the worst of it. After all that work to explain how we can make sense of people’s behavior in terms of something like a utility function (albeit a distorted one), I think there’s often a simpler explanation still: Regret aversion under total neglect of probability.
Neglect of probability is self-explanatory: You totally ignore the probability. But what’s regret aversion, exactly? Unfortunately I’ve had trouble finding any good popular sources on the topic; it’s all scholarly stuff. (Maybe I’m more cutting-edge than I thought!)
The basic idea that is that you minimize regret, where regret can be formalized as the difference in utility between the outcome you got and the best outcome you could have gotten. In effect, it doesn’t matter whether something is likely or unlikely; you only care how bad it is.
This explains insurance and lottery tickets in one fell swoop: With insurance, you have the choice of risking a big loss (big regret) which you can avoid by paying a small amount (small regret). You take the small regret, and buy insurance. With lottery tickets, you have the chance of getting a large gain (big regret if you don’t) which you gain by paying a small amount (small regret).
This can also explain why a typical American’s fears go in the order terrorists > Ebola > sharks > > cars > cheeseburgers, while the actual risk of dying goes in almost the opposite order, cheeseburgers > cars > > terrorists > sharks > Ebola. (Terrorists are scarier than sharks and Ebola and actually do kill more Americans! Yay, we got something right! Other than that it is literally reversed.)
Dying from a terrorist attack would be horrible; in addition to your own death you have all the other likely deaths and injuries, and the sheer horror and evil of the terrorist attack itself. Dying from Ebola would be almost as bad, with gruesome and agonizing symptoms. Dying of a shark attack would be still pretty awful, as you get dismembered alive. But dying in a car accident isn’t so bad; it’s usually over pretty quick and the event seems tragic but ordinary. And dying of heart disease and diabetes from your cheeseburger overdose will happen slowly over many years, you’ll barely even notice it coming and probably die rapidly from a heart attack or comfortably in your sleep. (Wasn’t that a pleasant paragraph? But there’s really no other way to make the point.)
If we try to estimate the probability at all—and I don’t think most people even bother—it isn’t by rigorous scientific research; it’s usually by availability heuristic: How many examples can you think of in which that event happened? If you can think of a lot, you assume that it happens a lot.
And that might even be reasonable, if we still lived in hunter-gatherer tribes or small farming villages and the 150 or so people you knew were the only people you ever heard about. But now that we have live TV and the Internet, news can get to us from all around the world, and the news isn’t trying to give us an accurate assessment of risk, it’s trying to get our attention by talking about the biggest, scariest, most exciting things that are happening around the world. The amount of news attention an item receives is in fact in inverse proportion to the probability of its occurrence, because things are more exciting if they are rare and unusual. Which means that if we are estimating how likely something is based on how many times we heard about it on the news, our estimates are going to be almost exactly reversed from reality. Ironically it is the very fact that we have more information that makes our estimates less accurate, because of the way that information is presented.
It would be a pretty boring news channel that spent all day saying things like this: “82 people died in car accidents today, and 1657 people had fatal heart attacks, 11.8 million had migraines, and 127 million played the lottery and lost; in world news, 214 countries did not go to war, and 6,147 children starved to death in Africa…” This would, however, be vastly more informative.
In the meantime, here are a couple of counter-heuristics I recommend to you: Don’t think about losses and gains, think about where you are and where you might be. Don’t say, “I’ll gain $1,000”; say “I’ll raise my income this year to $41,000.” Definitely do not think in terms of the percentage price of things; think in terms of absolute amounts of money. Cheap expensive things, expensive cheap things is a motto of mine; go ahead and buy the $5 toothbrush instead of the $1, because that’s only $4. But be very hesitant to buy the $22,000 car instead of the $21,000, because that’s $1,000. If you need to estimate the probability of something, actually look it up; don’t try to guess based on what it feels like the probability should be. Make this unprecedented access to information work for you instead of against you. If you want to know how many people die in car accidents each year, you can literally ask Google and it will tell you that (I tried it—it’s 1.3 million worldwide). The fatality rate of a given disease versus the risk of its vaccine, the safety rating of a particular brand of car, the number of airplane crash deaths last month, the total number of terrorist attacks, the probability of becoming a university professor, the average functional lifespan of a new television—all these things and more await you at the click of a button. Even if you think you’re pretty sure, why not look it up anyway?
Perhaps then we can make prospect theory wrong by making ourselves more rational.