Oct 15, JDN 2458042
Today I’m trying something a little different. This post will assume a lot less background knowledge than most of the others. For some of my readers, this post will probably seem too basic, obvious, even boring. For others, it might feel like a breath of fresh air, relief at last from the overly-dense posts I am generally inclined to write out of Curse of Knowledge. Hopefully I can balance these two effects well enough to gain rather than lose readers.
Here are four core statistical concepts that I think all adults should know, necessary for functional literacy in understanding the never-ending stream of news stories about “A new study shows…” and more generally in applying social science to political decisions. In theory shese should all be taught as part of a core high school curriculum, but typically they either aren’t taught or aren’t retained once students graduate. (Really, I think we should replace one year of algebra with one semester of statistics and one semester of logic. Most people don’t actually need algebra, but they absolutely do need logic and statistics.)
- Mean and median
The mean and the median are quite simple concepts, and you’ve probably at least heard of them before, yet confusion between them has caused a great many misunderstandings.
Part of the problem is the word “average”. Normally, the word “average” applies to the mean—for example, a batting average, or an average speed. But in common usage the word “average” can also mean “typical” or “representative”—an average person, an average family. And in many cases, particularly when in comes to economics, the mean is in no way typical or representative.
The mean of a sample of values is just the sum of all those values, divided by the number of values. The mean of the sample {1,2,3,10,1000} is (1+2+3+10+1000)/5 = 203.2
The median of a sample of values is the middle one—order the values, choose the one in the exact center. If you have an even number, take the mean of the two values on either side. So the median of the sample {1,2,3,10,1000} is 3.
I intentionally chose an extreme example: The mean and median of these samples are completely different. But this is something that can happen in real life.
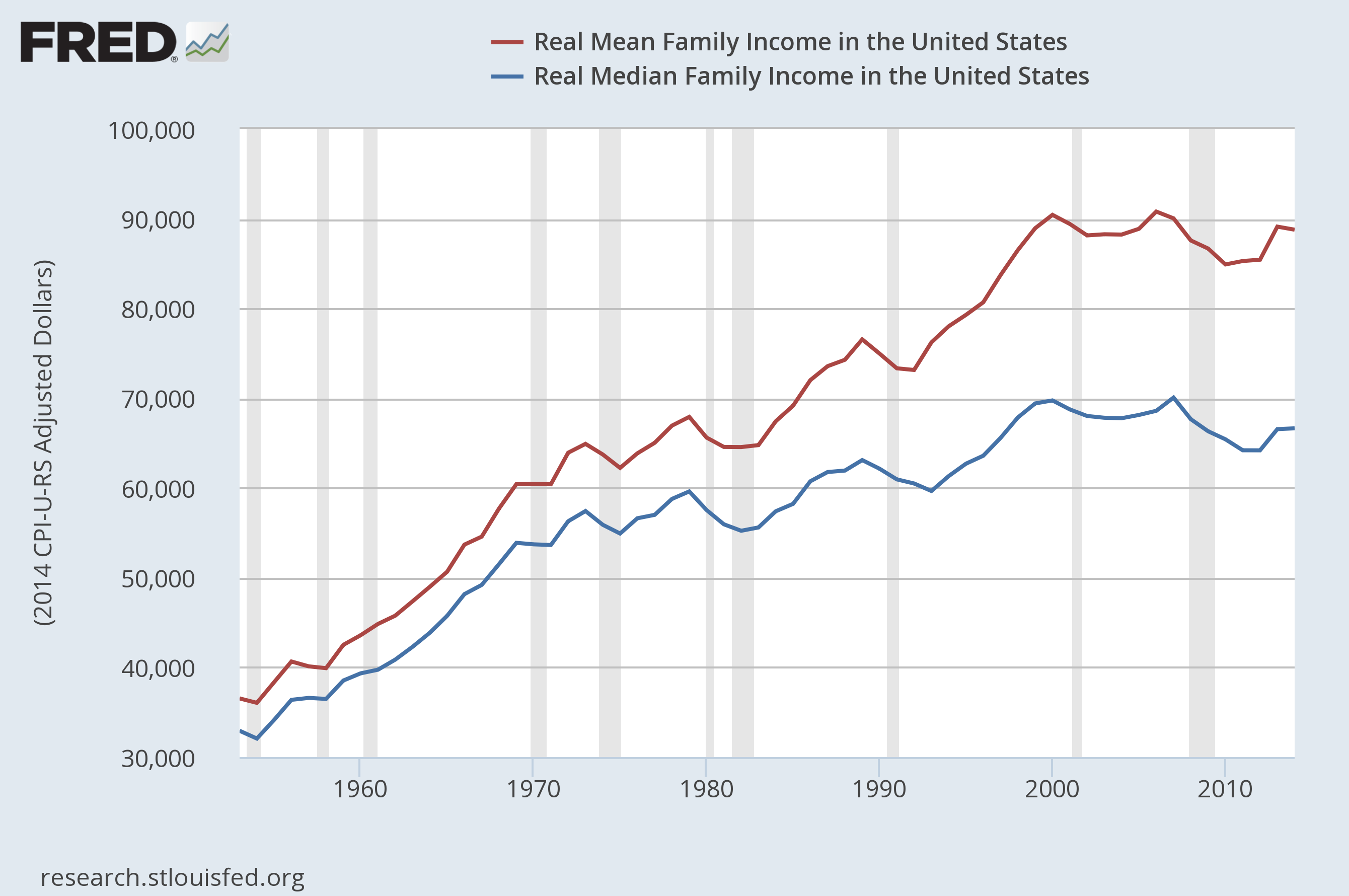
This is vital for understanding the distribution of income, because for almost all countries (and certainly for the world as a whole), the mean income is substantially higher (usually between 50% and 100% higher) than the median income. Yet the mean income is what is reported as “per capita GDP”, but the median income is a much better measure of actual standard of living.
As for the word “average”, it’s probably best to just remove it from your vocabulary. Say “mean” instead if that’s what you intend, or “median” if that’s what you’re using instead.
- Standard deviation and mean absolute deviation
Standard deviation is another one you’ve probably seen before.
Standard deviation is kind of a weird concept, honestly. It’s so entrenched in statistics that we’re probably stuck with it, but it’s really not a very good measure of anything intuitively interesting.
Mean absolute deviation is a much more intuitive concept, and much more robust to weird distributions (such as those of incomes and financial markets), but it isn’t as widely used by statisticians for some reason.
The standard deviation is defined as the square root of the mean of the squared differences between the individual values in sample and the mean of that sample. So for my {1,2,3,10,1000} example, the standard deviation is sqrt(((1-203.2)^2 + (2-203.2)^2 + (3-203.2)^2 + (10-203.2)^2 + (1000-203.2)^2)/5) = 398.4.
What can you infer from that figure? Not a lot, honestly. The standard deviation is bigger than the mean, so we have some sense that there’s a lot of variation in our sample. But interpreting exactly what that means is not easy.
The mean absolute deviation is much simpler: It’s the mean of the absolute value of differences between the individual values in a sample and the mean of that sample. In this case it is ((203.2-1) + (203.2-2) + (203.2-3) + (203.2-10) + (1000-203.2))/5 = 318.7.
This has a much simpler interpretation: The mean distance between each value and the mean is 318.7. On average (if we still use that word), each value is about 318.7 away from the mean of 203.2.
When you ask people to interpret a standard deviation, most of them actually reply as if you had asked them about the mean absolute deviation. They say things like “the average distance from the mean”. Only people who know statistics very well and are being very careful would actually say the true answer, “the square root of the sum of squared distances from the mean”.
But there is an even more fundamental reason to prefer the mean absolute deviation, and that is that sometimes the standard deviation doesn’t exist!
For very fat-tailed distributions, the sum that would give you the standard deviation simply fails to converge. You could say the standard deviation is infinite, or that it’s simply undefined. Either way we know it’s fat-tailed, but that’s about all. Any finite sample would have a well-defined standard deviation, but that will keep changing as your sample grows, and never converge toward anything in particular.
But usually the mean still exists, and if the mean exists, then the mean absolute deviation also exists. (In some rare cases even they fail, such as the Cauchy distribution—but actually even then there is usually a way to recover what the mean and mean absolute deviation “should have been” even though they don’t technically exist.)
- Standard error
The standard error is even more important for statistical inference than the standard deviation, and frankly even harder to intuitively understand.
The actual definition of the standard error is this: The standard deviation of the distribution of sample means, provided that the null hypothesis is true and the distribution is a normal distribution.
How it is usually used is something more like this: “A good guess of the margin of error on my estimates, such that I’m probably not off by more than 2 standard errors in either direction.”
You may notice that those two things aren’t the same, and don’t even seem particularly closely related. You are correct in noticing this, and I hope that you never forget it. One thing that extensive training in statistics (especially frequentist statistics) seems to do to people is to make them forget that.
In particular, the standard error strictly only applies if the value you are trying to estimate is zero, which usually means that your results aren’t interesting. (To be fair, not always; finding zero effect of minimum wage on unemployment was a big deal.) Using it as a margin of error on your actual nonzero estimates is deeply dubious, even though almost everyone does it for lack of an uncontroversial alternative.
Application of standard errors typically also relies heavily on the assumption of a normal distribution, even though plenty of real-world distributions aren’t normal and don’t even approach a normal distribution in quite large samples. The Central Limit Theorem says that the sampling distribution of the mean of any non-fat-tailed distribution will approach a normal distribution eventually as sample size increases, but it doesn’t say how large a sample needs to be to do that, nor does it apply to fat-tailed distributions.
Therefore, the standard error is really a very conservative estimate of your margin of error; it assumes essentially that the only kind of error you had was random sampling error from a normal distribution in an otherwise perfect randomized controlled experiment. All sorts of other forms of error and bias could have occurred at various stages—and typically, did—making your error estimate inherently too small.
This is why you should never believe a claim that comes from only a single study or a handful of studies. There are simply too many things that could have gone wrong. Only when there are a large number of studies, with varying methodologies, all pointing to the same core conclusion, do we really have good empirical evidence of that conclusion. This is part of why the journalistic model of “A new study shows…” is so terrible; if you really want to know what’s true, you look at large meta-analyses of dozens or hundreds of studies, not a single study that could be completely wrong.
- Linear regression and its limits
Finally, I come to linear regression, the workhorse of statistical social science. Almost everything in applied social science ultimately comes down to variations on linear regression.
There is the simplest kind, ordinary least-squares or OLS; but then there is two-stage least-squares 2SLS, fixed-effects regression, clustered regression, random-effects regression, heterogeneous treatment effects, and so on.
The basic idea of all regressions is extremely simple: We have an outcome Y, a variable we are interested in D, and some other variables X.
This might be an effect of education D on earnings Y, or minimum wage D on unemployment Y, or eating strawberries D on getting cancer Y. In our X variables we might include age, gender, race, or whatever seems relevant to Y but can’t be affected by D.
We then make the incredibly bold (and typically unjustifiable) assumption that all the effects are linear, and say that:
Y = A + B*D + C*X + E
A, B, and C are coefficients we estimate by fitting a straight line through the data. The last bit, E, is a random error that we allow to fill in any gaps. Then, if the standard error of B is less than half the size of B itself, we declare that our result is “statistically significant”, and we publish our paper “proving” that D has an effect on Y that is proportional to B.
No, really, that’s pretty much it. Most of the work in econometrics involves trying to find good choices of X that will make our estimates of B better. A few of the more sophisticated techniques involve breaking up this single regression into a few pieces that are regressed separately, in the hopes of removing unwanted correlations between our variable of interest D and our error term E.
What about nonlinear effects, you ask? Yeah, we don’t much talk about those.
Occasionally we might include a term for D^2:
Y = A + B1*D + B2*D^2 + C*X + E
Then, if the coefficient B2 is small enough, which is usually what happens, we say “we found no evidence of a nonlinear effect”.
Those who are a bit more sophisticated will instead report (correctly) that they have found the linear projection of the effect, rather than the effect itself; but if the effect was nonlinear enough, the linear projection might be almost meaningless. Also, if you’re too careful about the caveats on your research, nobody publishes your work, because there are plenty of other people competing with you who are willing to upsell their research as far more reliable than it actually is.
If this process seems rather underwhelming to you, that’s good. I think people being too easily impressed by linear regression is a much more widespread problem than people not having enough trust in linear regression.
Yes, it is possible to go too far the other way, and dismiss even dozens of brilliant experiments as totally useless because they used linear regression; but I don’t actually hear people doing that very often. (Maybe occasionally: The evidence that gun ownership increases suicide and homicide and that corporal punishment harms children is largely based on linear regression, but it’s also quite strong at this point, and I do still hear people denying it.)
Far more often I see people point to a single study using linear regression to prove that blueberries cure cancer or eating aspartame will kill you or yoga cures back pain or reading Harry Potter makes you hate Donald Trump or olive oil prevents Alzheimer’s or psychopaths are more likely to enjoy rap music. The more exciting and surprising a new study is, the more dubious you should be of its conclusions. If a very surprising result is unsupported by many other studies and just uses linear regression, you can probably safely ignore it.
A really good scientific study might use linear regression, but it would also be based on detailed, well-founded theory and apply a proper experimental (or at least quasi-experimental) design. It would check for confounding influences, look for nonlinear effects, and be honest that standard errors are a conservative estimate of the margin of error. Most scientific studies probably should end by saying “We don’t actually know whether this is true; we need other people to check it.” Yet sadly few do, because the publishers that have a strangle-hold on the industry prefer sexy, exciting, “significant” findings to actual careful, honest research. They’d rather you find something that isn’t there than not find anything, which goes against everything science stands for. Until that changes, all I can really tell you is to be skeptical when you read about linear regressions.