Apr 5 JDN 246136
I’ve been unable to find it, but several years ago someone famous wrote a sci-fi work entitled something like “A letter from the post-singularity” about how great life is after AI takes over everything. Today I thought I’d write a more realistic take on the path we actually seem to be on.
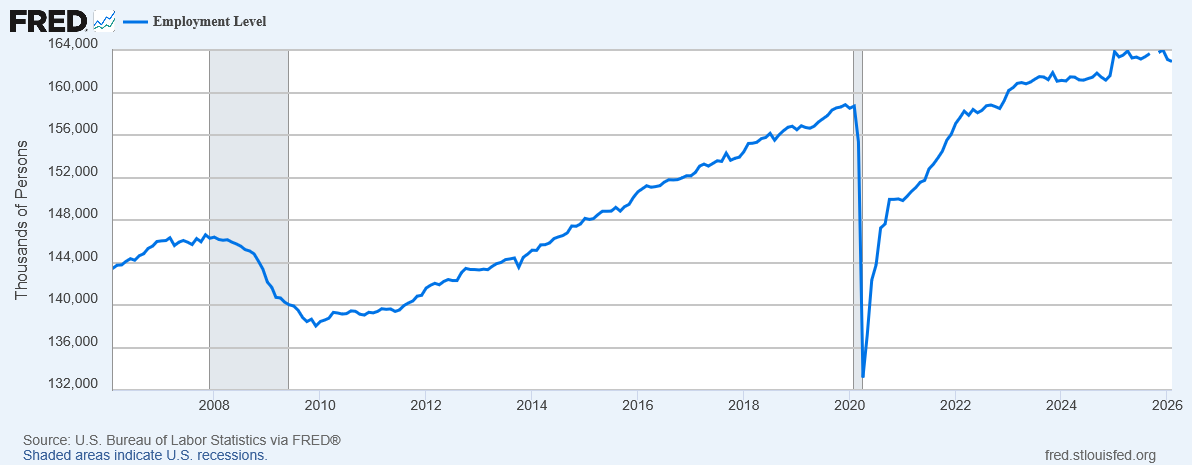
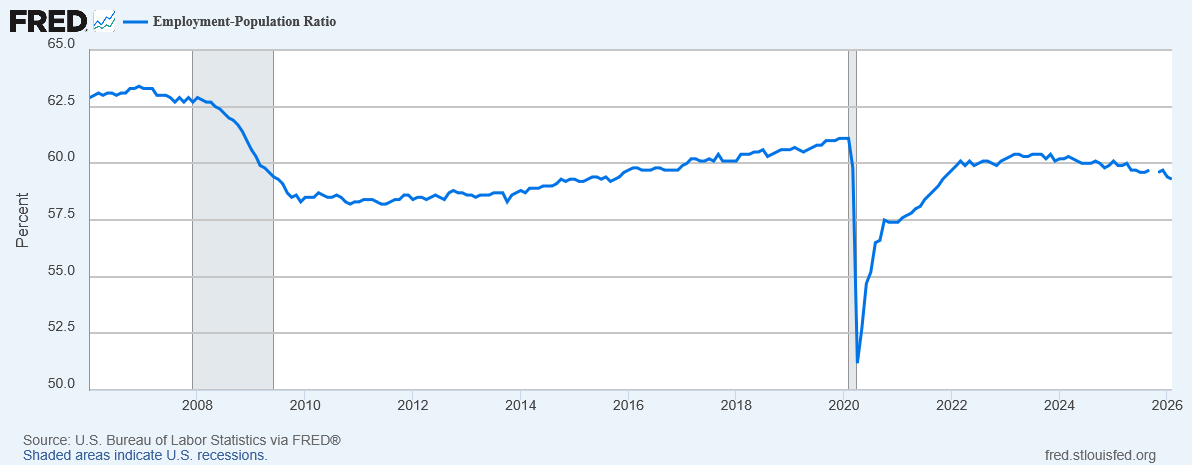
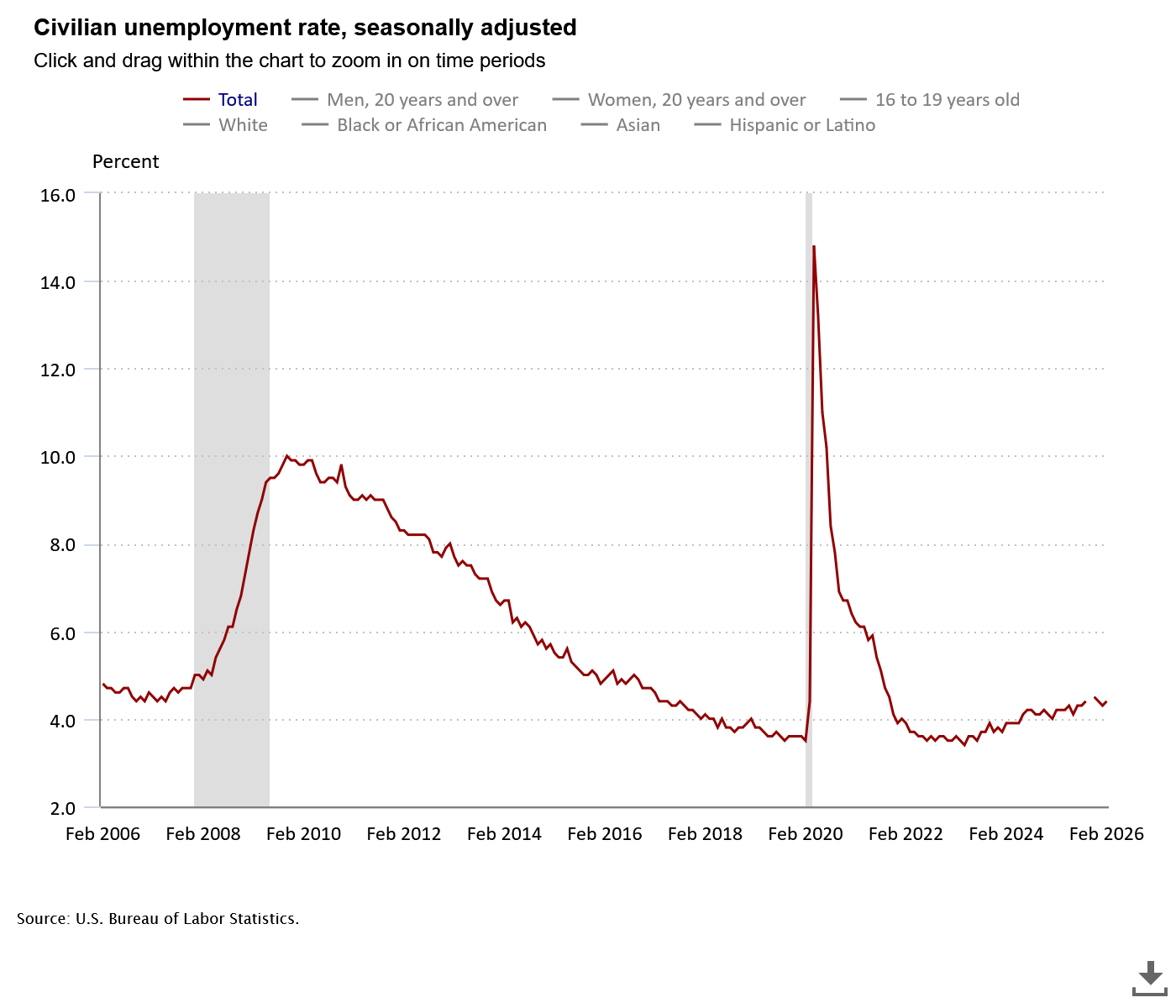
The year is 2073. Technically we still don’t have true AGI; as far as we can tell, AI still isn’t actually sentient and AIs aren’t people. (Some of us wonder, though. Philosophers debate it.) But that doesn’t really matter, because all white-collar work has been completely automated, and so has any blue-collar work that doesn’t require fine dexterity or unusual expertise. Plumbers and electricians are still doing all right (though they do more of their work at data centers than homes these days); sometimes I wish I’d apprenticed to be an electrician. Then again, the world can still only support so many electricians. AI managers command AI-run asteroid mines to extract ores to transport with AI-run spacecraft to Mars where AI-run factories process those ores and fabricate chips for more AIs that more AI-run spacecraft carry to Earth to be installed in AI-run data centers. And each time one gets sold, some trillionaire’s number goes up, and that’s the only thing people like him have ever cared about in their lives.
There are of course a handful of super-brilliant, super-creative, or just super-lucky individuals who manage to get rich making art or music or books or video games or whatever, but the vast majority of people who do art are still starving artists, just as they’ve always been, I guess. And the AI-generated stuff is good enough now that most of the time people will just use that instead of paying extra for the “authentic” “artisanal” stuff. (And most people can’t even tell the difference anyway.)
Harvard and Oxford still have professors, but most universities have fully automated teaching and most of their administration—and yet somehow tuition is barely any cheaper now than it was in your time, even adjusted for inflation. And if you were thinking of becoming a professor yourself? You should probably just go play prediction markets or something; you’d have better odds. The number of research papers published every year is astronomical, but they’re all written and reviewed by AI, rarely if ever even read by any human being, and so it seems like the actual progress of scientific knowledge has pretty much ground to a halt. (Seriously, how are there still string theorists? It’s been a century.) I guess corporate R&D still keeps on improving those graphics cards somehow; maybe they’ve discovered something important, but if they have, they’re keeping it to themselves. And I keep reading about amazing advancements done by AIs (especially in pure math that I’m not sure anyone understands), but none of it actually ever seems to affect anyone’s actual lives.
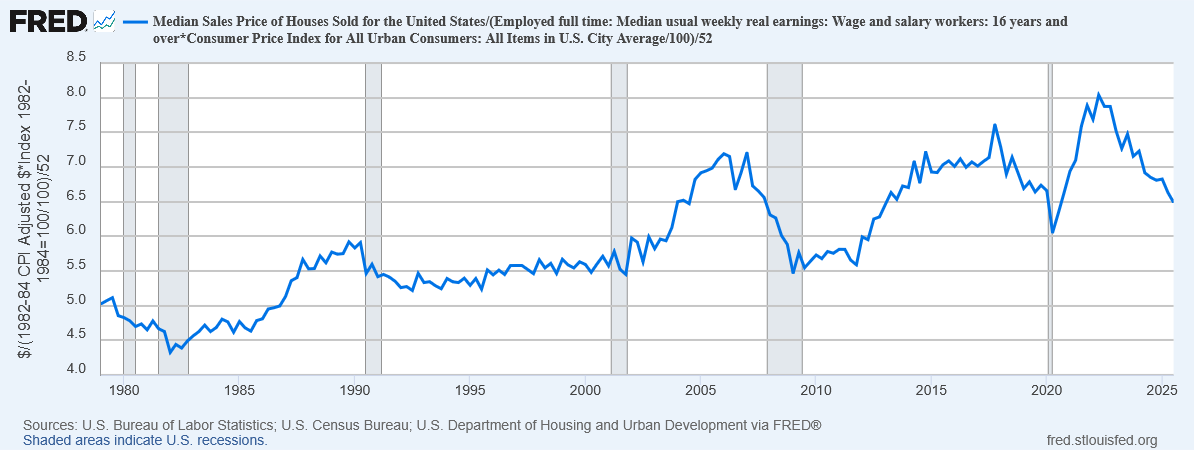
As for me, I live on UBI. Like 90% of people do. It’s enough to rent a cheap apartment (but own a home? Are you serious? Only millionaires own homes.), buy basically-adequate food (as long as you don’t eat out too much anywhere that’s not fast food), and pay for all the subscriptions to media services and home assistants and whatnot. What you make on UBI will only buy you the ad-supported versions, so while my fridge will order milk for me (delivered by drone in a couple of hours) and my robot maid will cook breakfast, fold the laundry and put the dishes in the dishwasher, my fridge is also constantly running ads and my maid will intersperse targeted sales pitches into its casual conversation. Sometimes I think I should just get rid of it (her?) and do my own cooking and cleaning myself, so I would never be able to sell it for half what I paid for it. If I could make some extra money, maybe I could at least upgrade to the ad-free subscription for my maid. (The Pro subscription and hardware addons to make her your girlfriend are just gross, but I’m sure they make tons of money.)
Every year, some politician makes a big deal about how the UBI trust fund is draining and will be gone in ten years or whatever; but it’s obvious that all they’d have to do to fix that would be raise the taxes on trillionaires a little bit, yet somehow that never seems to happen. But they also don’t cut UBI payments either, except sometimes to reduce our cost-of-living adjustments. I dunno; maybe they will really cut UBI payments in a few years. Or maybe we’ll get lucky and they’ll actually raise taxes for once.
At least I wasn’t dumb enough to move to Mars, where “employment is guaranteed!” but you have to pay a subscription for your oxygen.
My worst days are probably… about as bad as your worst days. Frankly they couldn’t be much worse, because sometimes I just want to die. Like a lot of people on UBI, I feel like a burden on society, like the world would be better off without me. Medicaid won’t cover neuroregulator implants, so I still take pills for my depression; they’re probably better than the pills you could get, but they’re still far from perfect.
My best days are maybe better than yours, maybe worse; it depends, I guess. If you’ve got cancer, your days are probably worse than mine, because we can pretty easily treat most cancers now. But if you’re healthy and you’ve got a steady job and a tight-knit community where you live, I’m guessing your days are better.
I have access to faster computers and faster Internet than you can probably imagine; my understanding was that back in the day you had to wait for downloads sometimes? Or even sometimes wait for webpages to load? What was that like? And your storage was measured in gigabytes, not petabytes? Humanity has never been so connected; human beings have never been so isolated. I theory I can contact anyone in the Solar System at the speed of light, but in practice my friends and I always seem to have trouble keeping in touch. (Oddly, it’s my best friend who lives on a station over Ganymede that I seem to stay in touch with best; we have to write full-length emails, because there’s no way to have a conversation on a ping of an hour and a half. It feels like being an old-timey pen pal, I guess.)
It’s not all bad. Some things are definitely better these days.
People often live to be 110 or even 120 nowadays. (So you might still be alive when I write this.) Rarely does anyone seem to make it past that, though; aging is just… really hard to beat. (The Boomers are finally almost gone, but Gen X is still gonna be with us for awhile yet.) We’ve cured a lot of the diseases that were bad in your time, but not all of them. And sometimes only people rich enough to pay for their own healthcare can afford the cures.
Language barriers are pretty much gone. If I wanna read something that was written in Japanese or Xhosa, I just have an AI translate it, and the translations are good enough now that you’d have to be really deeply-versed in the language to find any problems with it. Like, okay, maybe I’m not getting all the subtle connotations of Japanese literature, but was I ever going to actually learn kanji to read the originals? No. That kind of thing is for people with crazy obsessions.)
Our video games are definitely way better than yours. Characters with AI personalities that adapt in real time to how you behave. Procedurally-generated open worlds that can literally expand to the size of entire planets. (Actually, I vaguely remember reading you had a couple games that did something like the second one? Minecraft and Factorio, I think they were called? Impressive that you could pull that off on a gigaflop processor.) Worlds and factions that adapt to your actions and provide realistic consequences so that no two players’ experiences of the game are exactly the same. It’s easy to lose yourself in a game like that (especially if you’ve got a VR setup), and when you’re playing in such a rich, interesting world for hundreds of hours. you can sometimes forget how bleak things are back in the real world your flesh-and-blood body lives in. (But then you get hungry or have to pee and you get forced back into reality.)
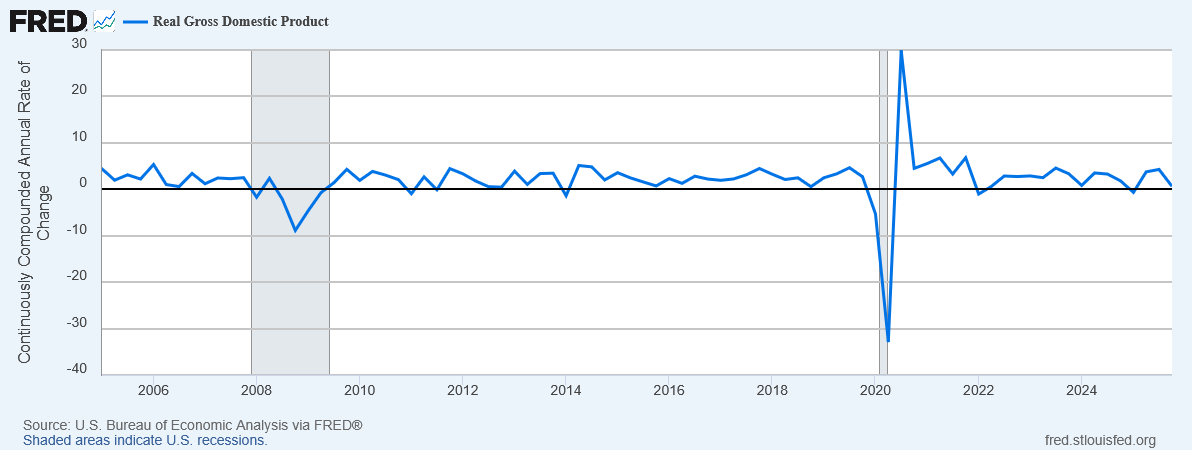
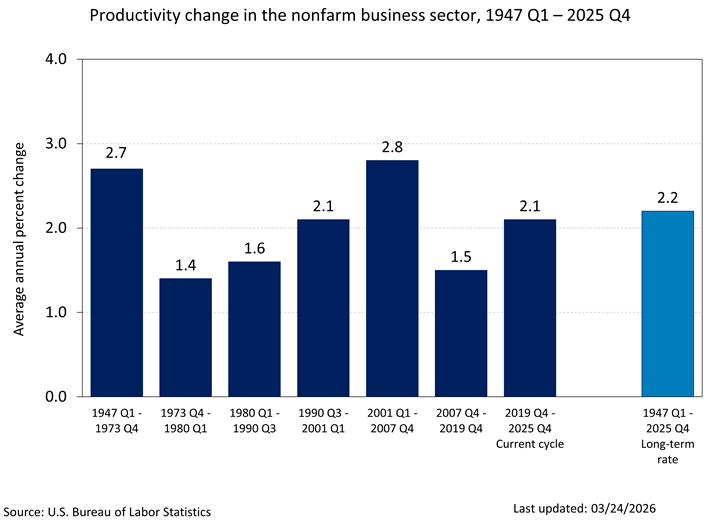
Economists keep telling us that per-capita GDP and productivity have never been higher, and that we have access to all these wonderful goods and services that previous generations could scarcely even imagine.
But if that’s true, why do I sometimes just want to die?