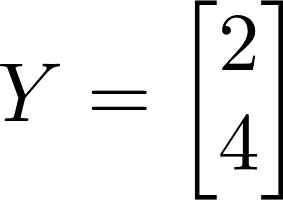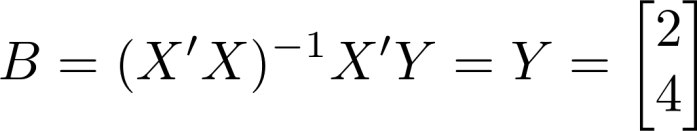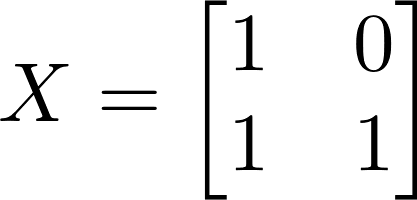Dec 31, JDN 2458119
“The state of macro is good,” wrote Oliver Blanchard—in August 2008. This is rather like the turkey who is so pleased with how the farmer has been feeding him lately, the day before Thanksgiving.
It’s not easy to say exactly where macroeconomics went wrong, but I think Paul Romer is right when he makes the analogy between DSGE (dynamic stochastic general equilbrium) models and string theory. They are mathematically complex and difficult to understand, and people can make their careers by being the only ones who grasp them; therefore they must be right! Nevermind if they have no empirical support whatsoever.
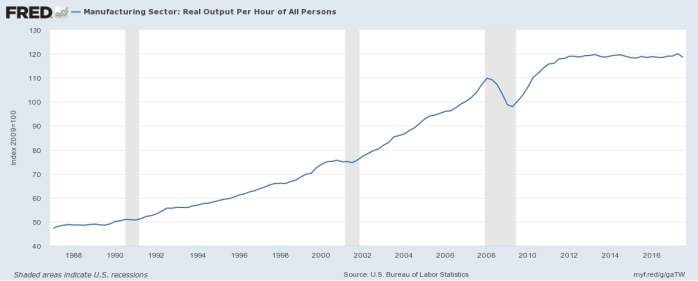
To be fair, DSGE models are at least a little better than string theory; they can at least be fit to real-world data, which is better than string theory can say. But being fit to data and actually predicting data are fundamentally different things, and DSGE models typically forecast no better than far simpler models without their bold assumptions. You don’t need to assume all this stuff about a “representative agent” maximizing a well-defined utility function, or an Euler equation (that doesn’t even fit the data), or this ever-proliferating list of “random shocks” that end up taking up all the degrees of freedom your model was supposed to explain. Just regressing the variables on a few years of previous values of each other (a “vector autoregression” or VAR) generally gives you an equally-good forecast. The fact that these models can be made to fit the data well if you add enough degrees of freedom doesn’t actually make them good models. As Von Neumann warned us, with enough free parameters, you can fit an elephant.
But really what bothers me is not the DSGE but the GTFO (“get the [expletive] out”); it’s not that DSGE models are used, but that it’s almost impossible to get published as a macroeconomic theorist using anything else. Defenders of DSGE typically don’t even argue anymore that it is good; they argue that there are no credible alternatives. They characterize their opponents as “dilettantes” who aren’t opposing DSGE because we disagree with it; no, it must be because we don’t understand it. (Also, regarding that post, I’d just like to note that I now officially satisfy the Athreya Axiom of Absolute Arrogance: I have passed my qualifying exams in a top-50 economics PhD program. Yet my enmity toward DSGE has, if anything, only intensified.)
Of course, that argument only makes sense if you haven’t been actively suppressing all attempts to formulate an alternative, which is precisely what DSGE macroeconomists have been doing for the last two or three decades. And yet despite this suppression, there are alternatives emerging, particularly from the empirical side. There are now empirical approaches to macroeconomics that don’t use DSGE models. Regression discontinuity methods and other “natural experiment” designs—not to mention actual experiments—are quickly rising in popularity as economists realize that these methods allow us to actually empirically test our models instead of just adding more and more mathematical complexity to them.
But there still seems to be a lingering attitude that there is no other way to do macro theory. This is very frustrating for me personally, because deep down I think what I would like to do as a career is macro theory: By temperament I have always viewed the world through a very abstract, theoretical lens, and the issues I care most about—particularly inequality, development, and unemployment—are all fundamentally “macro” issues. I left physics when I realized I would be expected to do string theory. I don’t want to leave economics now that I’m expected to do DSGE. But I also definitely don’t want to do DSGE.
Fortunately with economics I have a backup plan: I can always be an “applied micreconomist” (rather the opposite of a theoretical macroeconomist I suppose), directly attached to the data in the form of empirical analyses or even direct, randomized controlled experiments. And there certainly is plenty of work to be done along the lines of Akerlof and Roth and Shiller and Kahneman and Thaler in cognitive and behavioral economics, which is also generally considered applied micro. I was never going to be an experimental physicist, but I can be an experimental economist. And I do get to use at least some theory: In particular, there’s an awful lot of game theory in experimental economics these days. Some of the most exciting stuff is actually in showing how human beings don’t behave the way classical game theory predicts (particularly in the Ultimatum Game and the Prisoner’s Dilemma), and trying to extend game theory into something that would fit our actual behavior. Cognitive science suggests that the result is going to end up looking quite different from game theory as we know it, and with my cognitive science background I may be particularly well-positioned to lead that charge.
Still, I don’t think I’ll be entirely satisfied if I can’t somehow bring my career back around to macroeconomic issues, and particularly the great elephant in the room of all economics, which is inequality. Underlying everything from Marxism to Trumpism, from the surging rents in Silicon Valley and the crushing poverty of Burkina Faso, to the Great Recession itself, is inequality. It is, in my view, the central question of economics: Who gets what, and why?
That is a fundamentally macro question, but you can’t even talk about that issue in DSGE as we know it; a “representative agent” inherently smooths over all inequality in the economy as though total GDP were all that mattered. A fundamentally new approach to macroeconomics is needed. Hopefully I can be part of that, but from my current position I don’t feel much empowered to fight this status quo. Maybe I need to spend at least a few more years doing something else, making a name for myself, and then I’ll be able to come back to this fight with a stronger position.
In the meantime, I guess there’s plenty of work to be done on cognitive biases and deviations from game theory.